Introduzione all'architettura dei calcolatori |
|
Le macchine di von Neumann e le loro derivazioni appena analizzate sono tutte basate su un modello di computazione che prevede flussi di istruzioni eseguite con logica sequenziale, tranne laddove l'ordine di esecuzione sia esplicitamente dichiarato (ad esempio, nelle istruzioni di salto): questa restrizione è nota come il "collo di bottiglia di von Neumann" (von Neumann bottleneck). In presenza di flussi multipli di istruzioni, come nelle macchine di von Neumann parallele, possono inoltre sorgere grossi problemi dovuti all'ordinamento delle istruzioni non solo all'interno di un singolo flusso, ma soprattutto all'interno di flussi interagenti. Non sorprende pertanto come la ricerca nel campo delle architetture si sia spinta di recente a comprendere modelli di computazione diversi da quello di von Neumann.
I modelli di computazione di tipo dataflow sono caratterizzati dal fatto che il programmatore non è tenuto a descrivere minutamente la sequenza di esecuzione dei calcoli, ma deve solo specificare le relazioni di interdipendenza tra i dati. Diventa così possibile -- almeno in linea teorica -- scegliere, tra i molti possibili ordinamenti delle operazioni per l'esecuzione di un algoritmo, quello più adatto in relazione alle varie condizioni del sistema di elaborazione.
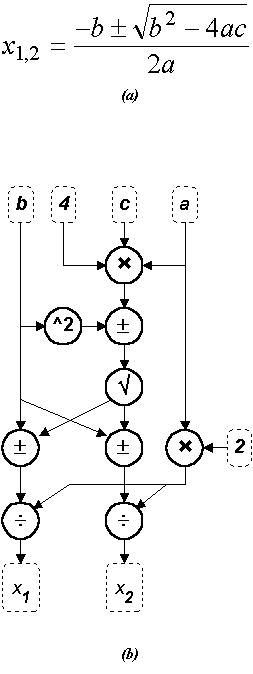
Il modello di computazione di una macchina dataflow può essere rappresentato mediante un grafo attraverso i cui rami (orientati) fluiscono i dati, e i cui nodi rappresentano trasformazioni sui dati. Alcuni nodi del grafo hanno soltanto rami entranti o soltanto rami uscenti, che rappresentano rispettivamente i dati di ingresso e i dati di uscita. Un nodo viene considerato in grado di iniziare le operazioni ad esso assegnate soltanto quando tutti i dati relativi ai suoi rami di ingresso sono resi disponibili dai nodi predecessori; eseguite tali operazioni, esso rende disponibile i risultati lungo tutti i suoi rami uscenti. A titolo di esempio, in Fig. 12 appare il modello di computazione dataflow per il calcolo delle soluzioni dell'equazione di secondo grado.
|
||
|
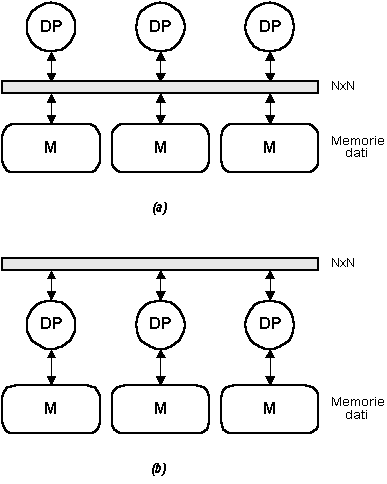
La macchina astratta per un sistema dataflow è naturalmente priva di processori di istruzioni, e può assumere due forme, in maniera simile a quanto abbiamo visto in precedenza nel caso dei processori vettoriali. Nella prima forma (Fig. 13a) tutte le memorie di dati sono ugualmente accessibili da tutti i processori di dati; nella seconda forma (Fig. 13b), ciascun processore ha la propria memoria locale, e i dati utilizzati dai vari processori transitano esclusivamente attraverso un commutatore NxN.
|
||
|
Via via che i costi dell'hardware diminuiscono e che determinate classi di algoritmi diventano sempre meglio conosciute, appare sempre più conveniente la realizzazione di architetture "dedicate" (o special-purpose (1)), rivolte cioè alla soluzione di una classe ristretta di problemi, con l'obiettivo di conseguire le massime prestazioni possibili compatibilmente con le tecnologie hardware disponibili. E' questo, ad esempio, il caso dell'elaborazione di immagini, dove si presenta di frequente la necessità di sottoporre una mole enorme di dati ad algoritmi relativamente semplici ma con struttura essenzialmente ripetitiva.
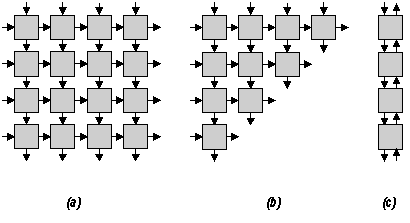
Una classe importante delle architetture dedicate è costituita dalle architetture sistoliche, che possono sfruttare al massimo il parallelismo intrinseco di certi algoritmi mediante un'organizzazione in strutture estremamente regolari. I sistemi sistolici, introdotti all'inizio degli anni '80 [8] [12] [13] [14], si basano su un insieme di celle interconnesse, ciascuna capace di eseguire determinate semplici operazioni entro un intervallo di tempo detto ciclo di clock. All'inizio di ogni ciclo, ogni cella acquisisce nuovi dati, li elabora e rende disponibili i risultati ad altre celle prima che il ciclo termini; se i cicli si susseguono l'uno dietro l'altro, i dati viaggiano attraverso la struttura in maniera molto simile a quanto abbiamo visto accadere nelle macchine pipeline, e sono presenti alle uscite in un flusso continuo. Contrariamente alle macchine pipeline, però, in un'architettura sistolica sono la topologia della struttura e le operazioni eseguite dalle singole celle a determinare il tipo di algoritmo eseguito.
Ad esempio, in Fig. 14a è rappresentata una tipica architettura sistolica bidimensionale, dove ogni cella comunica con quattro celle circostanti; all'inizio di un dato ciclo di clock le celle della colonna di sinistra e della riga superiore acquisiscono dati dall'esterno, li elaborano e li rendono disponibili alle rispettive uscite; al ciclo successivo, questi dati passano alle celle del livello successivo, mentre le celle esterne acquisiscono un nuovo insieme di dati dall'esterno, e così via. I dati sono disponibili all'uscita della struttura dalle celle della riga inferiore e della colonna di destra, praticamente alla stessa velocità con cui vengono acquisiti all'ingresso: la complessità dell'algoritmo non influisce sul tempo di calcolo, ma solo sulla struttura della rete, sulla complessità della singola cella, e sul ritardo costante con cui un dato di uscita segue il corrispondente dato di ingresso.
|
||
|
La ricerca attuale nel campo delle architetture sistoliche è rivolta alla scoperta delle architetture e delle funzioni di cella che più si adattano all'implementazione di determinati algoritmi. Per via della loro semplicità e regolarità strutturale e della loro capacità di trattare enormi quantità di dati nell'unità di tempo, le architetture sistoliche si prestano in modo particolare ad essere implementate sotto forma di circuiti integrati VLSI, con prospettive molto promettenti per determinate aree di applicazione.
Uno dei fattori che stanno alla base delle prestazioni sempre più spinte che è possibile ottenere dai calcolatori risiede nella velocità dei dispositivi elettronici di cui è costituito l'hardware, che al giorno d'oggi raggiunge senza difficoltà parecchie decine di milioni di operazioni al secondo. Tuttavia, la ricerca neurofisiologica ha stabilito senza possibilità di dubbio che la velocità dei neuroni, le cellule specializzate che si trovano nel cervello e nel sistema nervoso dell'uomo e dell'animale, non supera il migliaio di operazioni al secondo, e anzi in molti casi è decisamente ancora più bassa. Come mai allora qualunque persona è in grado di osservare e descrivere una scena, di leggere e apprezzare un libro, di ascoltare e comprendere un discorso, senza alcuno sforzo visibile, quando compiti anche più semplici di questi non sono neanche lontanamente realizzabili sui più potenti calcolatori attuali?
La risposta sta probabilmente nel fatto che i neuroni, il cui comportamento può sotto certi aspetti essere assimilato a quello di un processore di dati relativamente semplice, sono presenti nel sistema nervoso umano in numero incredibilmente grande, più prossimo ai 1000 che non ai 100 miliardi, e che essi sono fittissimamente interconnessi tramite un numero di fibre nervose 10 o 100 volte maggiore. Da questa osservazione è scaturita l'idea di replicare -- su scala ovviamente di gran lunga più piccola -- quella che si ritiene essere l'architettura del sistema nervoso o di sue porzioni (ad esempio, il sistema visivo o il sistema uditivo).
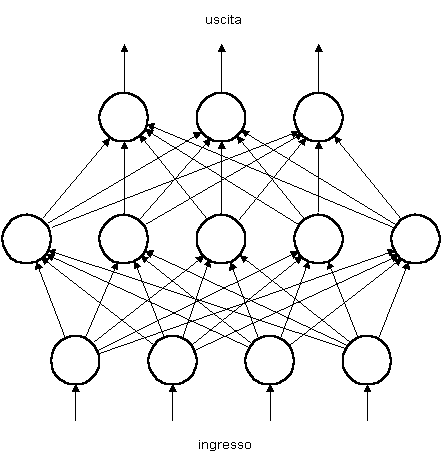
Una tipica rete neurale (artificiale) è costituita da un certo numero di semplici unità di elaborazione, chiamate neuroni (2), connessi tra di loro in maniera più o meno regolare (Fig. 15).
|
||
|
Ciascun neurone calcola una funzione a partire dai suoi ingressi e in base al valore di questa emette un segnale di uscita, che viene trasmesso ad altri neuroni attraverso le connessioni. Ad ogni connessione è associato un numero, chiamato peso della connessione, in base a cui viene alterato il segnale trasportato dalla connessione. Alcune connessioni sono adibite ad acquisire i segnali di ingresso provenienti dal mondo esterno, ed altre connessioni sono riservate per la generazione dei segnali di uscita.
Una volta applicati i dati di ingresso, la rete viene lasciata libera di evolversi fin quando raggiunge uno stato stabile, in corrispondenza del quale vengono prelevati i segnali di uscita. Una particolarità unica delle strutture neurali, che non trova alcun riscontro nei modelli computazionali tradizionali, consiste nel fatto che i valori dei pesi da assegnare alle connessioni per la soluzione di un determinato problema non sono quasi mai noti a priori; la rete viene infatti inizializzata con pesi arbitrari e viene quindi sottoposta a un periodo di addestramento, nel corso del quale vengono applicate delle coppie ingresso/uscita esemplificative e vengono modificati i valori dei pesi secondo una varietà di algoritmi. Al termine dell'addestramento, si trova che la rete è riuscita in un certo senso a "generalizzare" dagli esempi applicati, ed è in grado di fornire uscite corrette anche in corrispondenza di ingressi significativamente diversi da quelli applicati durante il periodo di apprendimento.
La memoria di una rete neurale non è dunque localizzata, come nei calcolatori tradizionali, in una o più unità specifiche, ma è distribuita lungo le connessioni tra i vari neuroni. Questo fatto ha diverse implicazioni importanti, tra cui quella notevolissima chiamata fault tolerance (tolleranza ai guasti): mentre in un normale calcolatore l'interruzione di un solo conduttore può provocare immediatamente errori gravissimi nel sistema, in una rete neurale l'alterazione di un numero limitato di connessioni non causa di solito anomalie significative nel suo comportamento.
Le prime strutture neurali apparvero, sotto forme rudimentali, fin dalla fine degli anni '40, ma furono praticamente abbandonate negli anni '60 di fronte all'esiguità dei risultati conseguiti e all'affermazione dei sistemi di elaborazione tradizionali. Da qualche anno, tuttavia, sono state introdotte nuove strutture e nuovi algoritmi di apprendimento le cui proprietà hanno riacceso nuovi interessi [2]; oggi la ricerca nel campo sta conoscendo una vera e propria esplosione, e sembra molto promettente per il prossimo futuro. Tuttavia, non sono ancora disponibili solidi fondamenti teorici per la descrizione del comportamento delle reti neurali, e la maggior parte delle analisi su queste strutture è stata di conseguenza condotta attraverso simulazioni su normali calcolatori; inoltre, non è ancora chiaro se, come e quando queste architetture potranno essere direttamente implementate in hardware, né è possibile prevedere in quale misura e in quali campi di applicazione esse riusciranno a competere con i calcolatori tradizionali.
|
|||||||
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-12-06 19:43