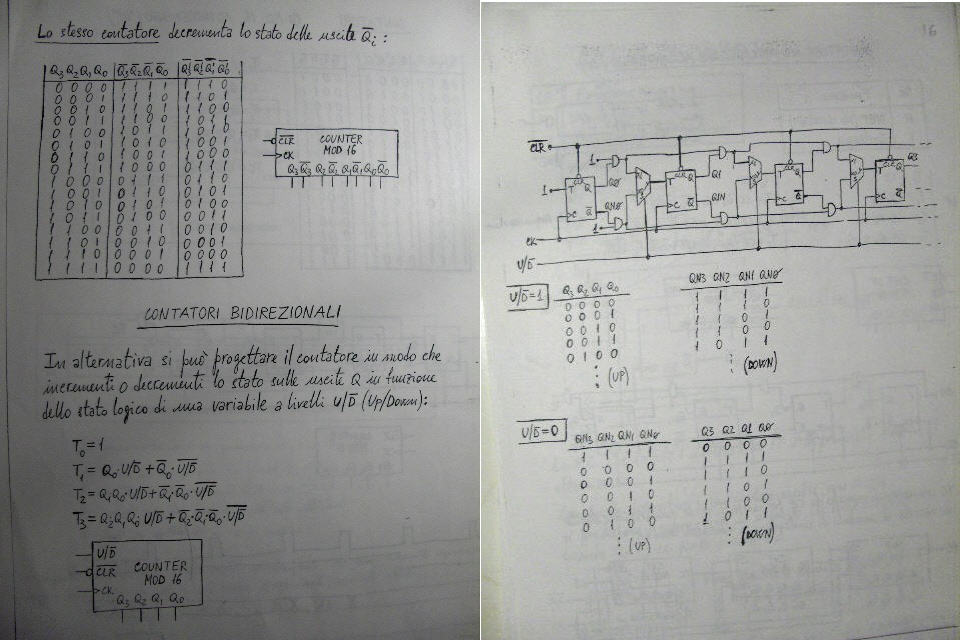
| Perche' mai il circuito dovrebbe essere
incalcolabile? Intanto, se un'uscita e' funzione di se stessa, il circuito
e' tipicamente sequenziale, anziche' combinatorio (l'abbiamo visto a
lezione, quando abbiamo progettato i primi flip-flop e il latch D,
ricorda?).
Questo circuito, tuttavia, e' piuttosto speciale, poiche', pur avendo
un loop combinatorio -- il che porterebbe a pensare che si tratta di un
circuito asincrono, dunque dotato di memoria -- in realta' continua a
comportarsi come circuito combinatorio, ossia dove le uscite sono funzione
solo degli ingressi attuali e non della loro storia, come vedremo tra
breve.
Come si fa ad analizzarlo? Ci sono due vie, l'una analitica (scriviamo
le equazioni che regolano i livelli logici sui vari nodi, e ricaviamo le
funzioni ingresso-uscita) e l'altra, piu' semplice ed immediata, che
consiste nel costruire la tavola di verita' e da questa ricavare le
funzioni ingresso-uscita.
Intanto cominciamo ad osservare che il circuito e' perfettamente
simmetrico, il che significa che se io riesco a ricavare ad esempio la
funzione y1 = f (x1, x2, x3) posso poi ottenere direttamente le altre due
semplicemente ruotando le variabili:
y2 = f (x2, x3, x1)
y3 = f (x3, x1, x2)
Questo significa allora che non e' necessario valutare tutte e otto le
possibili combinazioni di ingresso, ma e' sufficiente studiare che cosa
accade con le seguenti combinazioni:
(x1 x2 x3) = (0 0 0), (1 0 0), (1 1 0), (1 1 1)
tutti gli altri risultati li ottengo per simmetria ruotando sia le
variabili di ingresso che quelle di uscita.
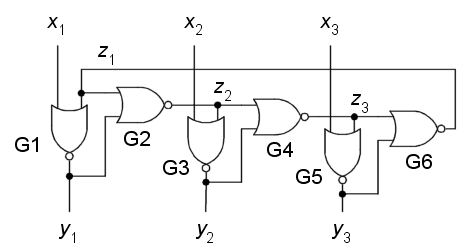
Adesso segua l'analisi sulla figura che le mando in allegato, dove ho
dato dei nomi ai nodi interni del circuito e alle singole porte, per
facilitarne il riferimento. Nel seguito, indichero' con x* la negazione di
x.
kautz.gif
Primo caso (x1 x2 x3 = 0 0 0) - Per le proprieta' dell'operatore NOR,
G1 G3 e G5 si comportano da invertitori rispetto a z1 z2 z3, ossia avremo
y1 = z1*, y2 = z2*, y3 = z3*. Di conseguenza, ciascuna delle porte G2 G4
G5 vedra' ai propri ingressi due livelli complementari, e quindi per le
proprieta' del NOR tutte e tre non potranno che avere uscita 0. Dunque,
essendo z1 = z2 = z3 = 0, avremo anche y1 = y2 = y3 = 1.
Secondo caso (x1 x2 x3 = 1 0 0) - Intanto sara' sicuramente y1 = 0. Le
porte G3 G5 si comportano da invertitori rispetto a z2 z3; G4 e G6 vedono
ai propri ingressi due livelli complementari; e dunque sara' z3 = z1 = 0;
e quindi z2 = 1. In definitiva, avremo y1 = 0, y2 = 0, y3 = 1.
Terzo caso (x1 x2 x3 = 1 1 0) - Intanto sara' sicuramente y1 = y2 = 0.
La porta G5 si comporta da invertitore rispetto a z3; G6 vede ai propri
ingressi due livelli complementari e dunque sara' sicuramente z1 = 0.
Pertanto avremo z2 = 1, z3 = 0; con conseguente y3 = 1.
Quarto e ultimo caso (x1 x2 x3 = 1 1 1), il piu' interessante. Le
uscite saranno senz'altro y1 = y2 = y3 = 0. Tuttavia, avremo anche z2 =
z1* = z3 = z2*, che NON e' una contraddizione! Significa semplicemente che
il loop combinatorio che comprende i nodi z1 z2 z3 entra in oscillazione;
ma e' anche vero che questa oscillazione, ossia questa variazione continua
di z1 z2 z3 *NON* influenza minimamente le uscite y1 y2 y3, che continuano
a restare tranquillamente fisse a zero!
A questo punto, sfruttando le simmetrie di cui dicevamo prima, possiamo
costruire la nostra tavola di verita':
x1 x2 x3 y1 y2 y3
--------------------
0 0 0 1 1 1
0 0 1 0 1 0
0 1 0 1 0 0
0 1 1 1 0 0
1 0 0 0 0 1
1 0 1 0 1 0
1 1 0 0 0 1
1 1 1 0 0 0
Adesso basta costruire un mappa di Karnaugh ad esempio per la sola y1,
ed otterremo
y1 = x1* x2 + x1* x3* = x1* (x2 + x3*)
Le altre due funzioni sono ottenute da questa per rotazione delle
variabili, o da analoga analisi sulla tavola di verita':
y2 = x2* (x3 + x1*)
y3 = x3* (x1 + x2*)
Questa categoria di circuiti e' stata scoperta nel 1970, con lo scopo
di dimostrare che in determinate circostanze e' *necessario* introdurre
loop combinatori per realizzare un sistema di funzioni combinatorie col
*minimo* numero possibile di porte. Ovviamente, circuiti di questo genere
hanno solo interesse accademico ma non vengono mai utilizzati in pratica,
poiche' l'oscillazione che ha luogo quando gli ingressi sono tutti a 1
assorbe una gran quantita' di energia dall'alimentazione. |